用 PickSkill 15 分鐘研究一檔新股
完整的首輪股票研究工作流 —— 商業模式、財務、估值、技術配置、風險 —— 15 分鐘用 chat 與指標工具完成。
過去要花 2–3 小時的首輪股票研究,用對的工作流可以 15 分鐘做完。 不是因為跳過步驟 —— 框架還是涵蓋商業模式、財務、估值、技術配置與風險 —— 而是因為 PickSkill 把資料蒐集步驟壓縮到數秒,讓你保留真正需要的那 15 分鐘:做判斷。這篇教學是首輪研究的正典工作流。任何你在考慮的新名字,在決定是否加入 觀察名單 或投入更多研究時間之前,先用它。
核心要點
- 5 步,約 15 分鐘總計。 商業模式 → 財務 → 估值 → 技術 → 風險。每一步一個 prompt。
- 框架強制結構化思考 —— 不會跳到「我該買嗎?」之前先回答上游問題。
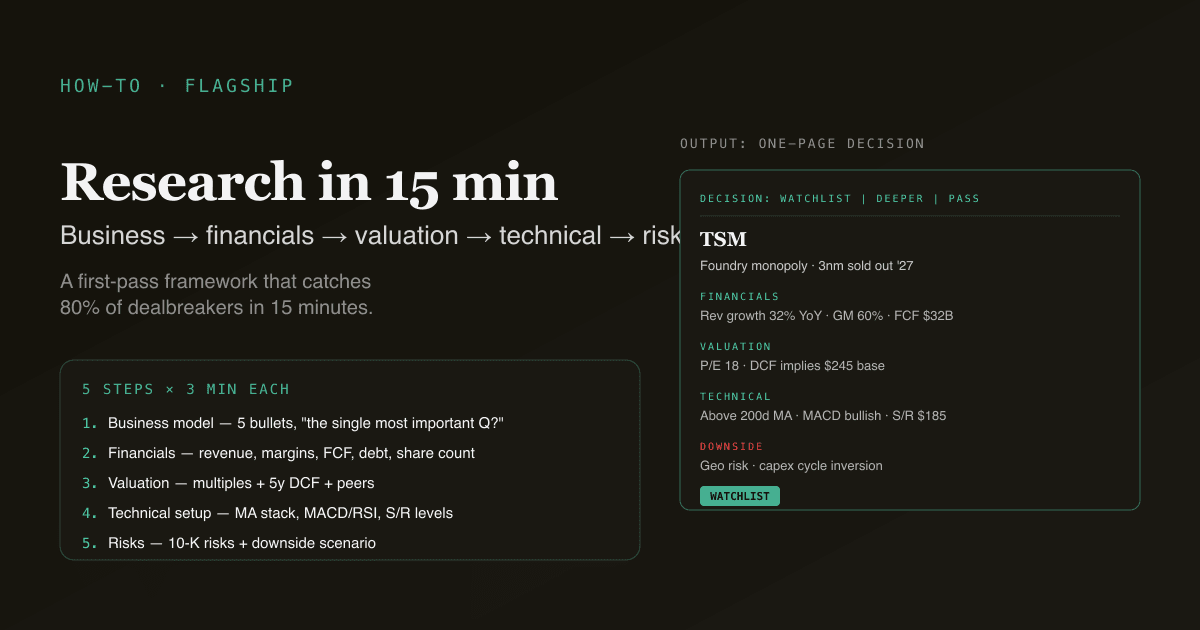
- 輸出一頁總結,適合加入 觀察名單 或剔除這個名字。
- 快速版(15 分鐘)抓到 80% 的致命瑕疵。 慢速版(2+ 小時深度工作)只在快速版說「有趣」後才需要。
- 適用美股、港股、A股 —— PickSkill 拉取市場合宜的公開文件。
為什麼重要
多數散戶在首輪研究階段就絆倒。兩個常見失敗:
- 直接跳到看圖。 「圖看起來不錯」不是論點。沒有先檢查底層商業模式與財務,你買的是價格形態。
- 被細節淹沒。 在判斷一檔名字是否值得更深工作前,把完整 10-K、8-K、最近財報電話會議逐字稿、所有分析師報告通讀一遍。等你看完已花 4 小時,而那是一檔你在第一小時用結構化框架就會剔除的名字。
15 分鐘首輪工作流是剔除過濾器。多數你研究的名字會不通過。重點是每檔花 15 分鐘,並把 2 小時深度版保留給通過首輪的名字。
5 步工作流
步驟 1 —— 商業模式(3 分鐘)
打開 /chat。貼上這個 prompt:
用 5 個 bullet 摘要 [代號]:
1. 這家公司實際做什麼(1 句話)
2. 營收拆分 —— 前 3 個 segment 與其占比
3. 前 3 大客戶或客戶集中度
4. 前 3 大競爭對手
5. 這個事業最需要做對的單一最關鍵問題
PickSkill 會根據最新 10-K 與近期新聞稿回傳一份精煉的商業模式摘要。「單一最關鍵問題」的框架強迫你想清楚什麼真正驅動這個事業 —— 是檢驗你理解這家公司還是只是這個代號的測試。
此階段警訊:5 個 bullet 後商業模式仍不清楚;單一客戶集中度高於 30%;看不到競爭護城河。看到這些就停 —— 名字不值接下來的 12 分鐘。
步驟 2 —— 財務健康(3 分鐘)
下一個 prompt:
拉 [代號] 過去 4 季與過去 3 年的:
- 營收與營收年增率
- 毛利率軌跡
- 營業利潤率軌跡
- 自由現金流(過去 4 季)
- 淨負債部位(現金 − 總負債)
- 股數年比變化(買回 vs 增發)
PickSkill 渲染成小表格。財務故事應該在一分鐘閱讀內變得連貫。
此階段警訊:營收成長明顯減速、毛利率無明顯原因壓縮、非有意成長投資造成的負自由現金流、無併購活動下年增 5%+ 的股數膨脹。
步驟 3 —— 估值快照(3 分鐘)
下一個 prompt:
對 [代號] 計算:
- 當前過去 P/E、預估 P/E、EV/EBITDA、P/B
- 每個倍數 5 年歷史區間(10–90 百分位)
- 當前倍數在歷史區間中的位置
- 當前倍數與 3 家最接近同業比較
- 快速 5 年 DCF —— 基準假設下隱含股價
PickSkill 回傳倍數、同業比較與快速 DCF(完整版見 60 秒建 DCF)。
此階段警訊:每個倍數都在 5 年區間頂端,但基本面沒有明顯加速能撐住;DCF 隱含股價低於當前 30%+;相對估值高於所有同業。
步驟 4 —— 技術配置(3 分鐘)
下一個 prompt:
對 [代號] 給我當前技術配置:
- 股價 vs 20 / 60 / 200 日均線
- 當前 MACD、RSI、KDJ 讀數
- 任何活躍的背離(常規或隱性)
- 最近支撐與阻力位
- 完整指標套件的 5 日 bucket 趨勢
PickSkill 拉 /indicators 資料並呈現多訊號對齊。
此階段警訊:極度超買進場(RSI > 75、所有指標釘住高位)、形成中的空頭背離、股價遠遠拉開 200 日 SMA。這些不是現在買的配置;是等回調的名字。
步驟 5 —— 風險(3 分鐘)
最後一個 prompt:
對 [代號] 列出:
- 最新 10-K 風險因素章節中的前 3 大風險
- 最近 4 季財報電話會議中的前 3 大風險
- 一個下行情境 —— 如果看多論點錯了,這檔股票會長什麼樣?
PickSkill 摘要 10-K 風險因素與最近管理層論述。下行情境問題是多數散戶跳過的 —— 也是抓到最昂貴錯誤的那一個。
此階段警訊:管理層提到的風險包括單一客戶集中、監管陰影、資產負債表壓力、或任何「持續經營疑慮」用語。這些不是自動取消資格,但應該重新框架倉位大小的對話。
怎麼編譯輸出
步驟 5 後,問:
把這場對話編成一頁總結讓我儲存:
- 2 句話商業模式
- 4 個 bullet 財務軌跡
- 估值總結配 3 行多頭 / 基準 / 空頭
- 技術配置狀態
- 前 3 大風險
- 決策:觀察名單、更深研究、或放棄
PickSkill 回傳結構化一頁。透過 chat 對話的書籤儲存。如果你決定把名字放上 觀察名單,這份一頁就是你的論點文件。
馬上試。 打開 /chat,對你正考慮的名字跑上面 5 個 prompt。整個流程含閱讀時間約 15 分鐘。
工作流捕捉到、臨時研究錯過的東西
1. 結構性剔除 vs 看圖型剔除
臨時研究常根據圖表外觀剔除名字(「看起來超買」),沒檢查事業是否值得在任何價格擁有。結構化工作流翻轉順序:商業模式 → 財務 → 估值 → 技術。如果商業或財務不通過,圖表無關緊要;如果商業與財務通過,圖表告訴你時機,不是可行性。
2. 下行情境問題
散戶研究最常跳過的一步是「空頭情境長什麼樣?」結構化工作流強制處理它。沒有它,你會過度偏多頭論點,對變異準備不足。
3. 多來源綜合在同一處
工作流把 10-K 資料、近期財報、當前倍數、同業比較、技術狀態拉進同一個對話。每一塊手動蒐集要 10–20 分鐘 —— PickSkill 把每一塊壓到數秒,留出時間做真正的思考。
股票研究的四個陷阱
- 跳過商業模式步驟。 知道一檔代號不等於知道這家公司。沒有 5 個 bullet 的摘要,你在交易代號,不是研究事業。
- 忽略下行情境。 多頭論點會自己冒出來;空頭論點要刻意挖出。如果你說不出空頭論點,你還沒做完研究。
- 把「全綠」當買進。 一檔基本面強、估值有吸引力、技術好的股票不會自動是買進 —— 有時是好賺的錢已賺完,接下來 12 個月可能就是橫盤。倉位大小與進場水位紀律重要。
- 不把輸出落到觀察名單或剔除。 15 分鐘首輪的全部重點是最後做決策。「再想想」是殺手 —— 消耗認知頻寬卻沒產出決策。逼自己落到觀察名單、更深研究、或放棄。
在 A股的應用
工作流在 A股與港股名字上完全一樣。兩個特別調整:
- 對 A股,「扣非淨利潤」(扣除非經常性損益後的淨利)是相關盈餘數字;PickSkill 在計算 A股 P/E 與 EPS 成長時預設用這個。
- A股估值倍數對多數板塊結構性低於美股同業。對比 A股歷史區間,而非美股對等項。
更全面的市場特定打法見 A股最好用的指標。
常見後續追問
15 分鐘首輪後:
- 「對 [代號] 做更深 DCF —— 完整敏感性表、按 segment 的營收預測。」
- 「比較 [代號] 與 3 家最接近同業的完整倍數堆疊與 FCF 成長。」
- 「從這場對話為 [代號] 生成投資人 deck。」(見 從 chat 生成投資人 deck。)
- 「把 [代號] 加到我的觀察名單,論點是:[...]」
- 「下次財報釋出時排程重新檢視 [代號]。」
延伸閱讀
- 60 秒建 DCF —— 首輪通過後的估值深挖。
- 30 分鐘讀 10-K —— 步驟 1 + 2 的手動深讀版。
- 怎麼建一個真的有用的觀察名單 —— 成功首輪後名字流向何處。
FAQ
為什麼 15 分鐘 —— 對一檔股票不嫌太快嗎? 對首輪 yes/no 決策,15 分鐘綽綽有餘 —— 多數名字應該在這個階段就被剔除。深度工作(建模特定假設、讀每一份近期 SEC 文件、訪談前員工)保留給少數通過首輪的名字。對遇到的每個名字花 4 小時是積極散戶的主要失敗模式。
能平行研究多檔名字嗎? 能 —— PickSkill 支援平行 chat 對話。許多使用者同時開 3–5 個對話,在每個上跑相同的 5 prompt 模板。結構讓批次研究實務可行。
如果 PickSkill 沒有這檔名字的資料怎麼辦? PickSkill 涵蓋多數美股(NYSE / NASDAQ)、港股(港交所)、A股(上交所 / 深交所)上市名字。對非常小或新近上市的名字,覆蓋可能較薄 —— PickSkill 會告訴你哪些資料點不可用,而不是憑空編造。
該儲存 chat 對話嗎? 該 —— PickSkill 每一個 chat 對話都持久化。對有用的研究對話加書籤以後參考。當你決定建立部位,chat 對話就是你如何形成論點的審計軌跡。
這跟一般的 ChatGPT 研究差在哪? PickSkill 的 chat 建立在即時公開文件、市場資料、計算指標之上 —— 不是模型的訓練資料。ChatGPT 會幻覺出營收數字與 P/E 比;PickSkill 在查詢時從原始來源拉取。這個結構性差異在財務與估值步驟最關鍵,過期或捏造的數字會徹底改變結論。